Working with OpenRefine
Overview
Teaching: 15 min
Exercises: 20 minQuestions
How can we bring our data into OpenRefine?
How can we sort and summarize our data?
How can we find and correct errors in our raw data?
Objectives
Create a new OpenRefine project from a CSV file.
Understand potential problems with file headers.
Use facets to summarize data from a column.
Use clustering to detect possible typing errors.
Understand that there are different clustering algorithms which might give different results.
Employ drop-downs to remove white spaces from cells.
Manipulate data using previous steps with undo/redo.
Lesson
Creating a new OpenRefine project
In Windows, you can start the OpenRefine program by double-clicking on the openrefine.exe file. Java services will start automatically on your machine, and OpenRefine will open in your browser. On a Mac, OpenRefine can be launched from your Applications folder. If you are using Linux, you will need to navigate to your OpenRefine directory in the command line and run ./refine.
OpenRefine can import a variety of file types, including tab separated (tsv), comma separated (csv), Excel (xls, xlsx), JSON, XML, RDF as XML, Google Spreadsheets. See the OpenRefine Importers page for more information.
In this first step, we’ll browse our computer to the sample data file for this lesson. In this case, we will be using data obtained from interviews of farmers in two countries in eastern sub-Saharan Africa (Mozambique and Tanzania). Instructions on downloading the data are available here.
Once OpenRefine is launched in your browser, the left margin has options to Create Project, Open Project, or Import Project. Here we will create a new project:
1. Click Create Project and select Get data from This Computer.
2. Click Choose Files and select the file SAFI_messy_openrefine.csv. Click Open or double-click on the filename.
3. Click Next>> under the browse button to upload the data into OpenRefine.
4. OpenRefine gives you a preview - a chance to show you it understood the file. If, for example, your file was really tab-delimited, the preview might look strange, you would choose the correct separator in the box shown and click Update Preview (bottom left). If this is the wrong file, click <<Start Over (upper left). There are also options to indicate whether the dataset has column headers included and whether OpenRefine should skip a number of rows before reading the data.
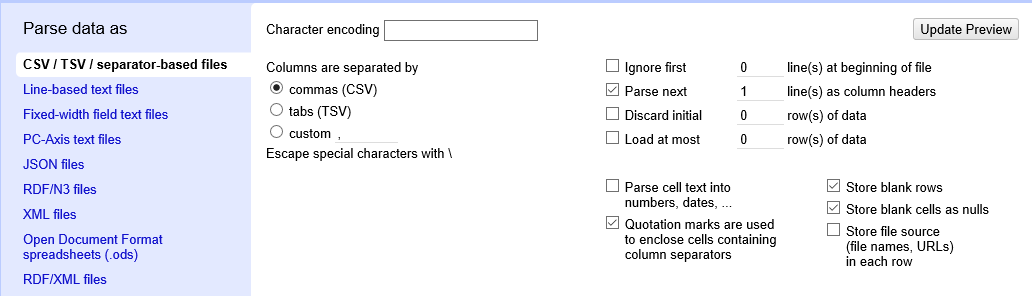
5. If all looks well, delete csv from the end of the name of your project and click Create Project>> (upper right). Files we export from the OpenRefine project will be given the name of the project, so if you end up creating multiple versions you will want to be sure and rename the file once you have exported it.
Note that at step 1, you could upload data in a standard form from a web address by selecting Get data from Web Addresses (URLs). However, this won’t work for all URLs.
The OpenRefine layout
Your project in OpenRefine will look like most other software that presents your data in a table. Here are some of the features:
- The number of rows is at the top left of the table window. This will change as you facet your data.
- You can look at rows or records. Records are created when there are rows that represent data for the same observation.
- You can choose how many rows you want to see at a time. The default is 10. There is no best choice, choose what you like.
- Because you can only see up to 50 rows at a time, if you have more data than that it will be on different pages. You navigate these with the buttons at the top right. (If these are obscured you might have to make your window bigger.)
- There are buttons in the left side of each column header that have a downward-pointing arrow. These open the menus with all of the functions to work with your data.
- The “All” column at the far left of the table window has three things - a star, a flag, and a number.
- The star and the flag can be selected by the row or all at once and can be used to choose rows manually.
- You can use the column menu button to facet by star or flag.
- The numbers are unique identifiers assigned by OpenRefine.
- You can use the column menu in the “All” column to transform multiple columns at once (this is a new feature, use carefully!).
- There are two tabs in the window on the far-left - Facet/Filter and Undo/Redo
- Facet/Filter will let you work with your facets to filter data. If your data doesn’t look right, check your facets and filters.
- Undo/Redo will allow you to step back or copy out the steps you have performed on your data.
We will go through the details of these different functions through the rest of the lesson.
Data Types in OpenRefine
Text
Any data can be classified as text. Like in a spreadsheet, text will be stored exactly as it was it was entered. Text facets will look for exact matches, taking extra spaces and case into account, and give you a list with a count of each value.
Text appears in the table in black and is left-justified.
Number
Numbers can be any numeric value and can include decimal places. If you try and classify a value that is not a number as a number you will get an error. You can perform mathematical calculations on numbers. They can be turned into text in a script by using toString().
Numbers appear in green and are right-justified.
Date
Dates are formatted in yyyy-mm-ddThh:mm:ss format. If no time was given it will default to midnight.
Dates are in green and are right-justified.
Boolean
Boolean values are either true or false. You will often see these if you have created a facet that separates values on whether or not they have a particular characteristic or if you perform a transform that is expressed as true or false.
Key Points
OpenRefine can import a variety of file types.
OpenRefine can be used to explore data using filters.
Clustering in OpenRefine can help to identify different values that might mean the same thing.
OpenRefine can transform the values of a column.